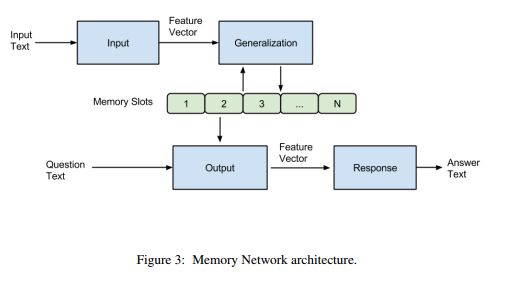
1 问题和数据集
1.1 问题
这是一篇以阅读理解为任务的文章,但在具体处理这个任务时,主要解决数据特征等的表示问题。在提取文本特征时,通常只对单词做词嵌入,而忽略了字符级的特征。
1.2 数据集
- CBT
- WDW
- SQuAD
2 目前已有方法
2.1 单词级表示
(1)from a lookup table
(2)每个单词用一个向量表示
(3) 擅长表示单词的语义
2.2 字符级表示
(1) 在单词的字符序列上运用RNN或者CNN,隐层状态合并来形成字符表示
(2)更适合子词形态建模
(3)可以减轻模型的OOV问题
2.3 单词级和字符级结合
(1)组合例子
- C2W model based on bidirectional LSTMs
gate units(Miyamoto & cho等提出的标量门控条件实际上并未提高性能)
(2)面临问题
- 对于频繁单词,可以准确估计,加入字符级表示可以产生干扰;
- 对于非频繁词,加入字符级会带来负面影响
3 本文提出的方法
本文提出了一个细粒度门控机制来合并单词级和字符级表示
4 具体内容
4.1 特征融合
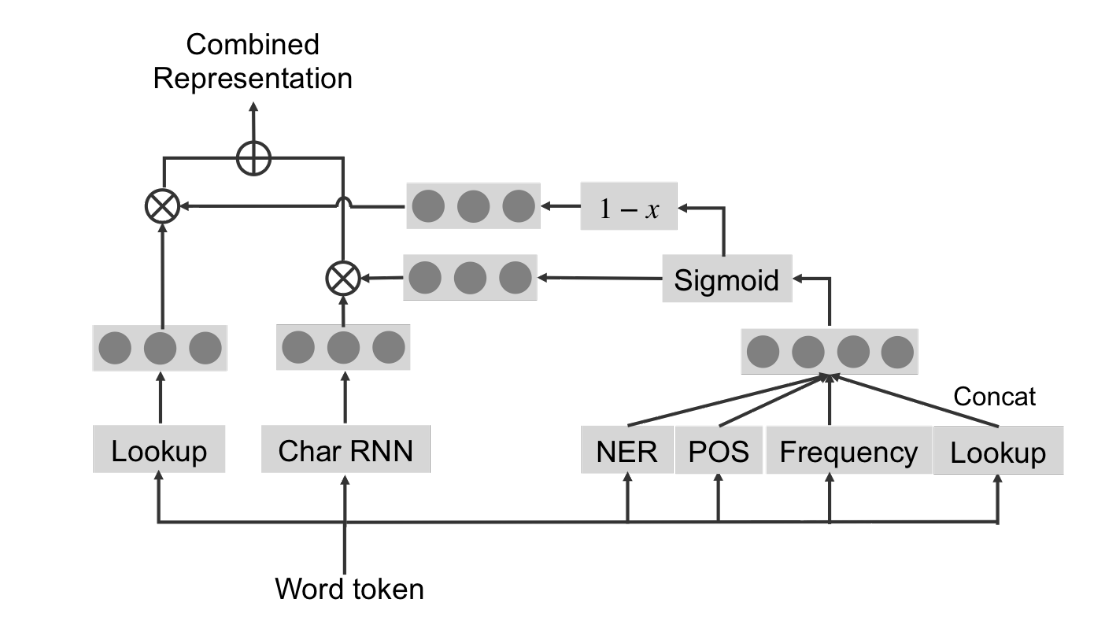
step1:对于单词特征,先做one-hot编码,再做word-embedding作为单词级表示(记为hp)
step2:对于字符特征,对单词里的每个字符做one-hot,再送人RNN,得到最后隐层向量来作为字符级表示(记为hq)
step3:利用NER,POS,Frequency特征等拼接而得到v,用来计算门控单元g。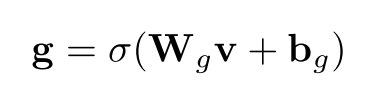
step4:将两个特征用门控机制来融合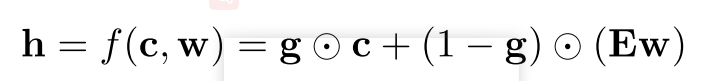
4.2 检索答案
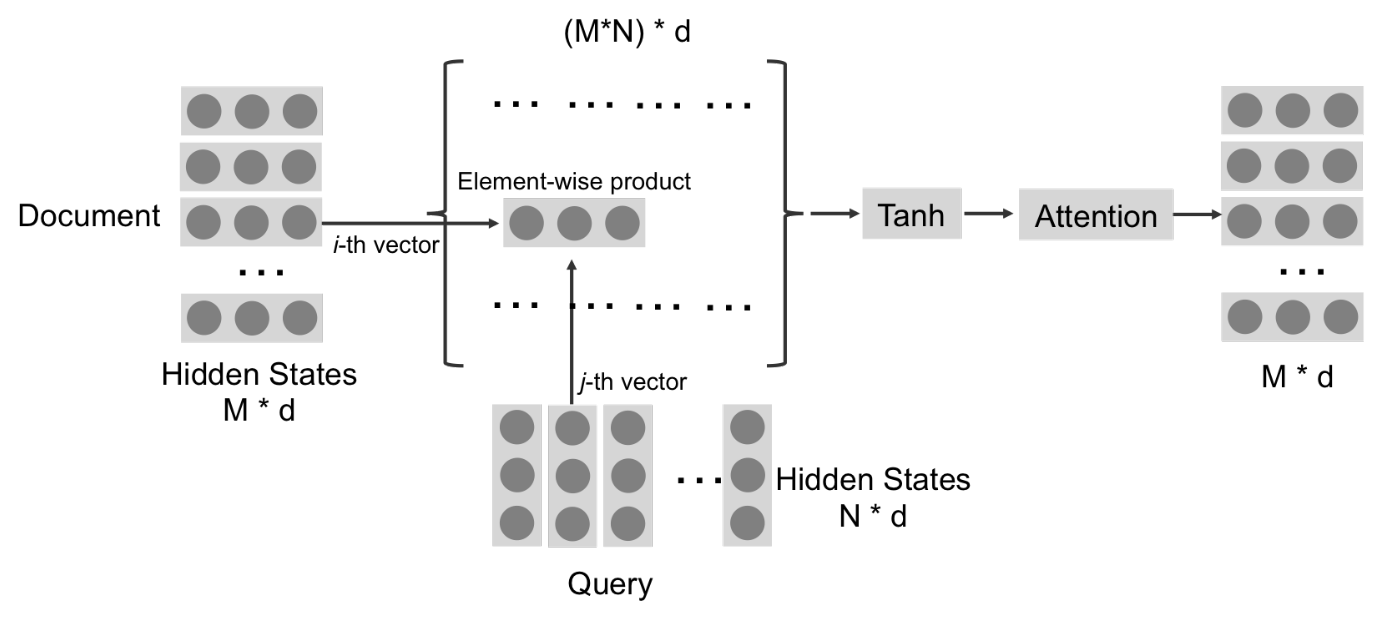
step1:计算Iij,于是qj可以看成是过滤Pi中的信息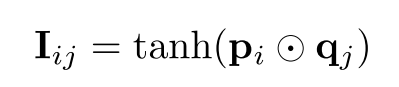
step2:计算hi,相当于在Iij上运用一个注意力机制,从而得到输出hi。(wi和wj分别是pi和qj的one-hot编码,原因是加强匹配,当k的值非常大时,这样的信息并不是完全保留。)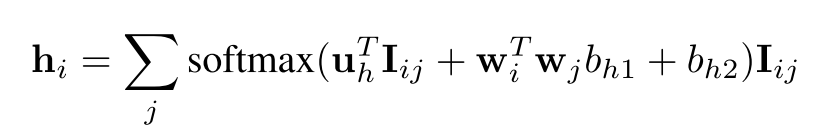
5 小结
(1).这是一个新的文本特征表示方法,当g值较大时,更多的信息流来自字符级,当g的信息较小时,更多的信息流来自单词级;
(2)本文使用的细粒度的门控机制,采用的是向量门而不是标量门;并且根据特征来设置门,能够更好的反映单词的属性
论文思维导图